🚀[2024-01-31]: We release the easy-to-use demo for multimodal hallucination detection on the Demo-EasyDetect!🌟
🔥[2023-12-15]: Our fact-conflicting hallucination detection benchmark is now available on the FactCHD. Abstract introduction can refer to the Home Page 😆
Part implementation of this project were assisted and inspired by the related hallucination toolkits including Factool, Woodpecker, and others. This repository also benefits from the public project from mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO, and MAERec. We follow the same license for open-sourcing and thank them for their contributions to the community.
Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UniHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UniHD through meticulous evaluation and comprehensive analysis. We also provide strategic insightson the application of specific tools for addressing various categories of hallucinations.

Figure 1: Unified view of multimodal hallucination detection.

Figure 2: Unified multimodal hallucination detection aims to identify and detect modality-conflicting hallucinations at various levels such as object, attribute, and scene-text, as well as fact-conflicting hallucinations in both image-to-text and text-to-image generation.
To further distinguish the difference between dataset and other existing ones, we elaborate the benchmark details in Figure. From the breadth perspective, the prior benchmarks are heavily focused on daily knowledge and common sense. The covered image format is also limited. Our benchmark aims to cover college-level knowledge with 30 image formats including diagrams, tables, charts, chemical structures, photos, paintings, geometric shapes, music sheets, medical images, etc. In the depth aspect, the previous benchmarks normally require commonsense knowledge or simple physical or temporal reasoning. In contrast, our benchmark requires deliberate reasoning with college-level subject knowledge.
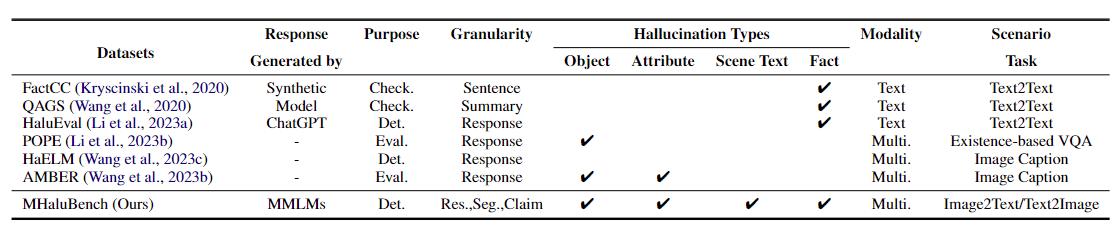
Table 1: A comparison of benchmarks w.r.t existing fact-checking or hallucination evaluation. “Check.” indicates verifying factual consistency, “Eval.” denotes evaluating hallucinations generated by different LLMs, and its response is based on different LLMs under test, while “Det.” embodies the evaluation of a detector’s capability in identifying hallucinations.
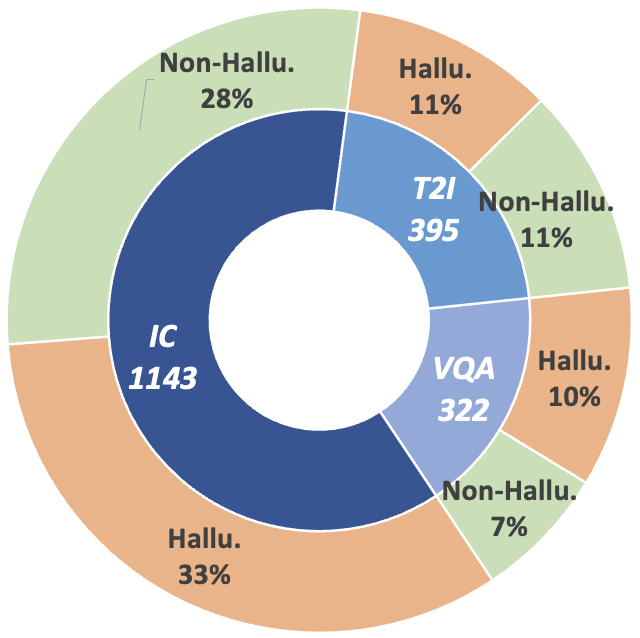
Figure 3: Claim-Level data statistics of MHaluBench. “IC” signifies Image Captioning and “T2I” indicates Text-to-Image synthesis, respectively
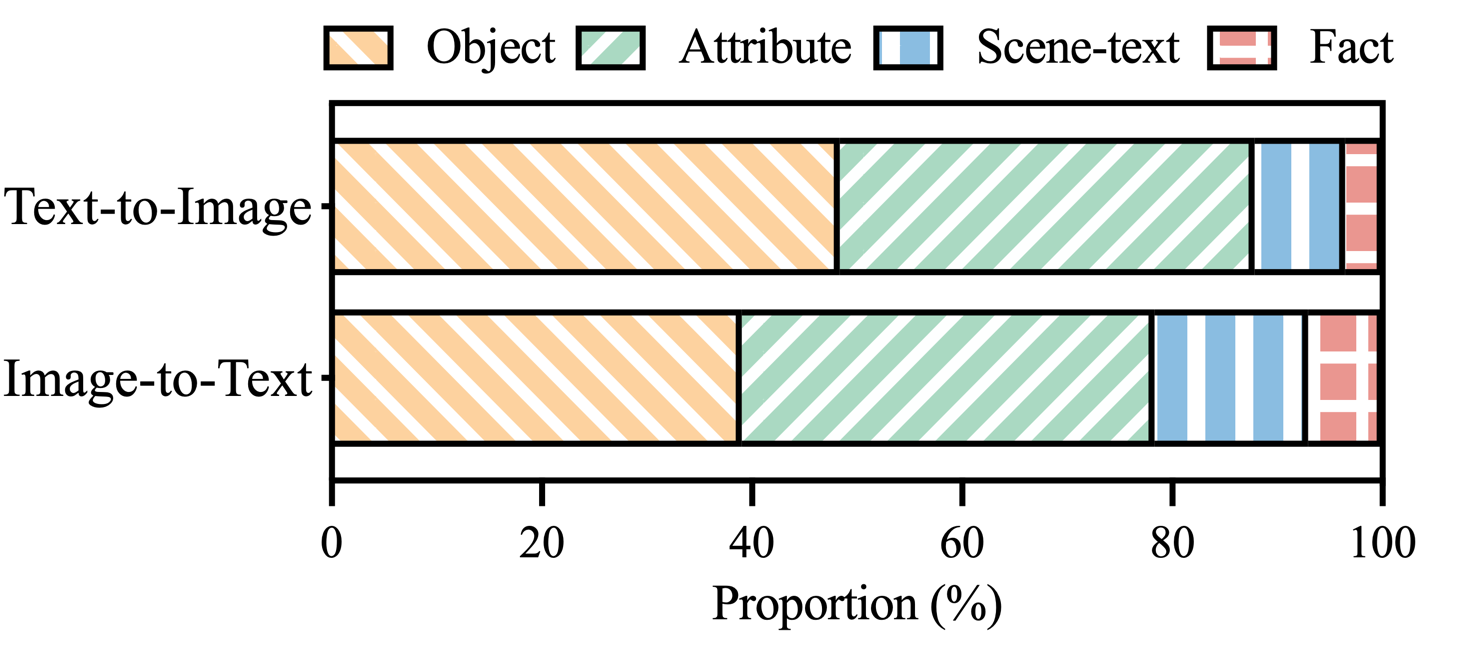
Figure 4: Distribution of hallucination categories within hallucination-labeled claims of MHaluBench..
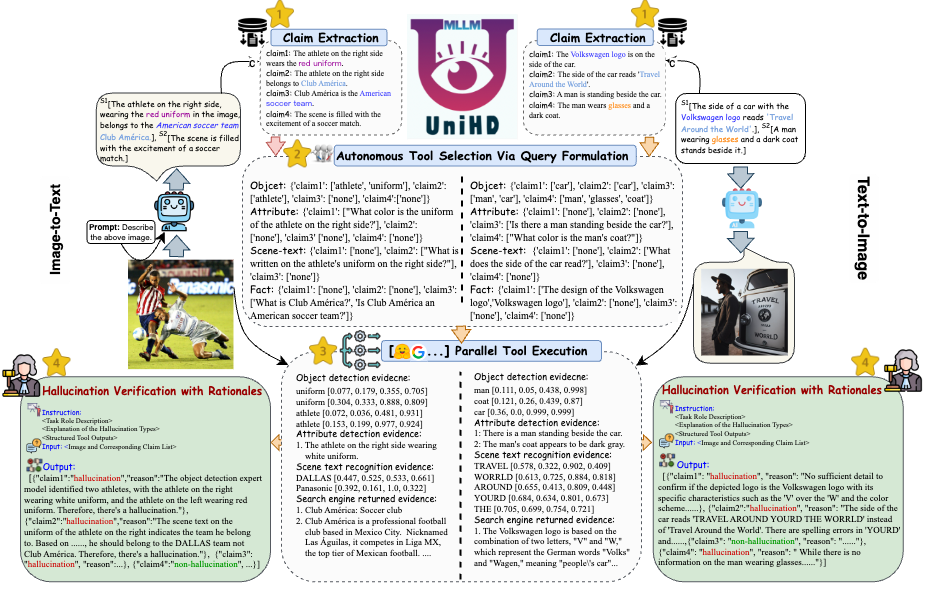
Figure 5: The specific illustration of UniHD for unified multimodal hallucination detection.
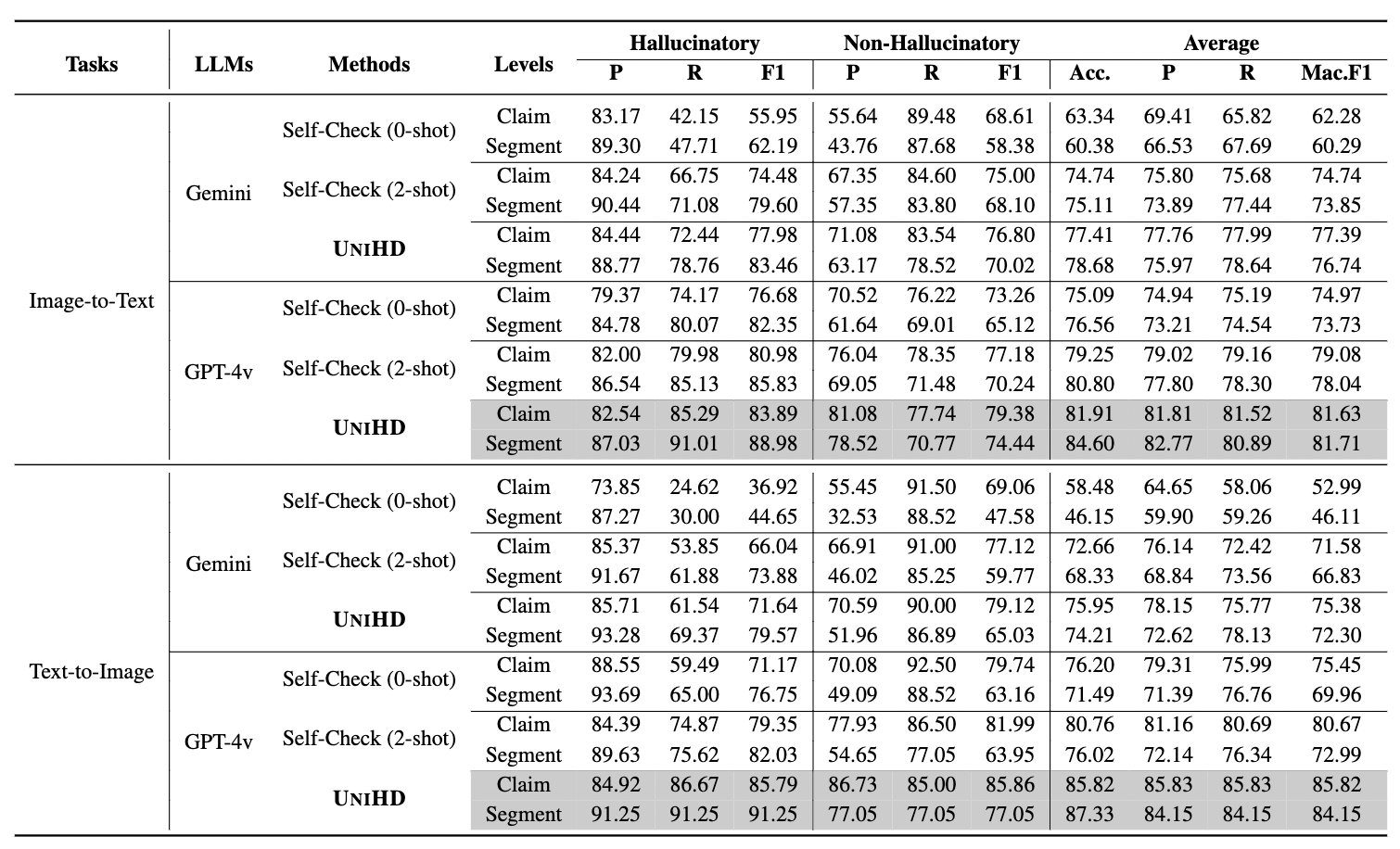
Table 2: Experimental results of UniHD powered by Gemini and GPT-4v on Image-to-Text Generation and Text-to-Image Generation. The default F1 score is Micro-F1, whereas Mac.F1 represents the Macro-F1 score.
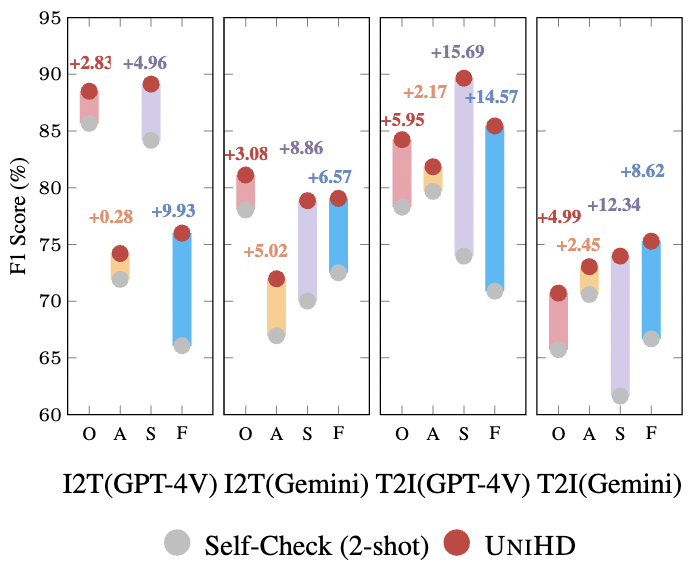
Figure 6: The statistical analysis was conducted on samples with hallucinatory labels. In this analysis, the x-axis labels “O”, “A”, “S” and “F” refer to object, attribute, scene-text, and fact, respectively

Figure 7: Case Study. The upper section depicts two exemplary cases where both UniHD and Self-Check (2-shot) arrive at correct judgments, with a comparative demonstration of UniHD providing explanations of superior reasonability. UniHD (a) reveals a failure case where the tool presents erroneous evidence, leading to an incorrect verification outcome. Conversely, UniHD (b) highlights a scenario where, despite the tool offering valid and correct evidence, GPT-4V persists in its original stance, resulting in a flawed verification
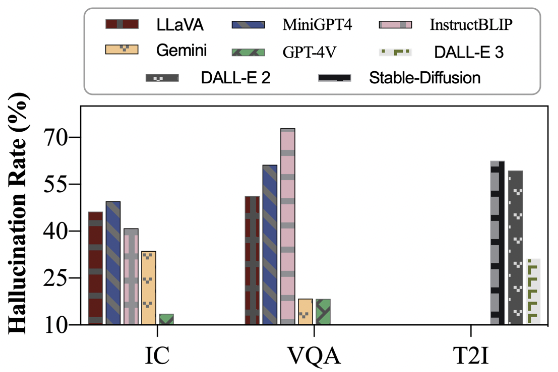
Figure 8: Comparison of claim-level hallucination ratios across MLLMs. We randomly select a set of 20 prompts from MHDEB for each of the IC, VQA, and T2I. Responses for these prompts are generated by each of the evaluated MLLMs
@article{chen23factchd,
author = {Xiang Chen and Duanzheng Song and Honghao Gui and Chengxi Wang and Ningyu Zhang and
Jiang Yong and Fei Huang and Chengfei Lv and Dan Zhang and Huajun Chen},
title = {FactCHD: Benchmarking Fact-Conflicting Hallucination Detection},
journal = {CoRR},
volume = {abs/2310.12086},
year = {2023},
url = {https://doi.org/10.48550/arXiv.2310.12086},
doi = {10.48550/ARXIV.2310.12086},
eprinttype = {arXiv},
eprint = {2310.12086},
biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{chen24unihd,
author = {Xiang Chen and Chenxi Wang and Yida Xue and Ningyu Zhang and Xiaoyan Yang and
Qiang Li and Yue Shen and Lei Liang and Jinjie Gu and Huajun Chen},
title = {Unified Hallucination Detection for Multimodal Large Language Models},
journal = {CoRR},
volume = {abs/2402.03190},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2402.03190},
doi = {10.48550/ARXIV.2402.03190},
eprinttype = {arXiv},
eprint = {2402.03190},
biburl = {https://dblp.org/rec/journals/corr/abs-2402-03190.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.


